|
 Key Concept 1 : What is stored in SaadaDBs ? Key Concept 1 : What is stored in SaadaDBs ?
All primary header keywords are stored in SaadaDBs except those discarded by the operator.
All entry attributes are also stored except those discarded by the operator.
Some keywords or columns are copied in Common Saada attributes (Position, names, WCS or user defined common attributes) in order to allow queries to retreive heterogeneous data. Query constraints are then applied on Saaada common attributes but not on specific product attributes.
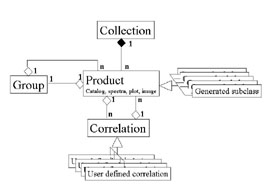
Key Concept 2 : Collections :
A collection is a container defined by the Saada operator.
It can simultaneously contain one set of images, one set of spectra and one set of source lists.
A SaadaDB can host as many collections as needed.
New collections can be added at any time.
All data contained in one collection are supposed to have some common points. For instance a collection can host data coming from one specific telescope, or data having a common scientific definition (galaxies, comets, ..).
Data contained in one collection can have various formats.
Queries can be limited to one or several given collections.
Collection names become keywords of the query language (SaadaQL)
Key Concept 3 : Classes :
Products of a given category (e.g. spectra) in a given collection can differ from one case to another.
They can either be quite similar or completely different. In fact they can even look similar but being different judging by (attribute name/unit/meaning conflicts).
Products are grouped in classes in order to avoid these conflicts.
The classification method is choosen by the operator.
Queries on data of a given class can be selected with constraints on any keywords whereas queries on products of different classes can only be selected with constraints on Saada attributes.
Class names become keywords of the query language (SaadaQL)
Key Concept 4 : Relationships :
Data can be linked to each other with qualified relationships.
Relationships are totally defined and populated by the operator.
A template whose aim is to help to populate relationships is given.
One relationship links all data of a given category (spectra or image or so on) and of a given collection with all data of a given category and of a given collection (loopbacks are allowed).
Relationships are identified by a name given by the operator and understood by the query language.
Links composing a relationship have a format given by the operator. They can be qualified with a set of values (distance, likelihood, pixel position, .....).
Relationships can be used to select data by applying constraints on the pattern formed by correlations (relationships) they are involved in. last update 2007-02-08
|